
イマーシブオーディオの進化と未来:オブジェクトベース音響からAIによる空間創造への技術的転回
- STUDIO 407 酒井崇裕

- 4月10日
- 読了時間: 10分
はじめに:音響体験における3次元的革命イマーシブオーディオ
オーディオ技術の歴史は、録音された音をいかに忠実に、そして臨場感を持って再現するかという絶え間ない探求の歴史です。エジソンの蓄音機から始まったモノラル録音、1950年代に主流となったステレオ、そして1990年代以降のサラウンドサウンドを経て、現代の音響技術は「イマーシブオーディオ(没入型音響)」という新たな地平に到達しました。従来のステレオが左右の広がり(二次元)を、サラウンドが水平方向の包囲感を提供していたのに対し、イマーシブオーディオは「高さ」の概念を加え、リスナーを全方位から包み込む三次元的な音響空間を構築します。


この技術的転換の核心にあるのは、従来の「チャンネルベース」から「オブジェクトベース」へのパラダイムシフトです。音を特定のスピーカーに割り当てるのではなく、音源を三次元空間内の座標情報を持つ独立した「オブジェクト」として扱うことで、再生環境に依存しない自由な音響配置が可能となりました。さらに、AI(人工知能)の急速な発展により、コンピュテーショナルオーディオという手法が登場し、ステレオ音源からの空間情報の抽出や、視覚情報に基づく音響空間の再構築が現実のものとなっています。

本報告書では、ドルビーアトモスとソニーの「360 Reality Audio」の技術的思想を分析し、それらが三次元的な空間情報を生成する原理を詳述します。また、AI時代における空間情報のキャプチャ技術、デジタルツインの構築、そして今後のイマーシブオーディオが向かうべき進化の方向性について詳しく考察します。
主要システムの現況と技術的思想:ドルビーアトモスと360 Reality Audio
現在のイマーシブオーディオ市場において、デファクトスタンダードの地位を確立しているのがドルビーアトモスであり、これに独自の音楽的アプローチで挑んでいるのがソニーの360 Reality Audio(以下、360RA)です。両者は共にオブジェクトベースの技術を採用していますが、その背景にある思想やエコシステムには顕著な差異が見られます。
ドルビーアトモス:映画から音楽、そして全方位への展開
ドルビーアトモスは、もともと映画館での多層的な音響表現のために開発された技術であり、その後ホームシアターや音楽配信へと応用範囲を広げてきました。その技術的思想の根幹は「ベッド(Bed)」と「オブジェクト(Object)」のハイブリッド構造にあります。ベッドは従来のサラウンドと同様に、最大7.1.2チャンネル(水平7、サブウーファー1、天井2)の固定された音響基盤を提供し、その上に三次元座標を持つ個別の音響オブジェクトを最大118個まで重ね合わせることができます。
この構造により、制作者は環境音やベースラインをベッドに固定しつつ、移動するヘリコプターの音や頭上を飛び交う楽器の音をオブジェクトとして自由に配置できます。ドルビーアトモスは映画産業で培われた強力なツールセットを持ち、主要な制作ソフトや配信プラットフォームに深く統合されています。この広範な採用実績が、現在の空間オーディオにおける優位性を支えています。
ソニー 360 Reality Audio:球状音場と音楽への没入
一方、ソニーの360RAは、音楽体験の純粋な没入を主眼に置いて開発されました。技術的には国際標準規格である「MPEG-H 3D Audio」をベースにしており、オープンな標準化路線を選択しています。360RAの最大の特徴は、リスナーを完全な「球状の音場(Spherical Sound Field)」の中に配置するという思想にあります。
ドルビーアトモスが映画的な「床と壁、天井」を意識した構成であるのに対し、360RAは全天球的な空間配置を基本とします。特に、足元から頭上までシームレスな音の移動を可能にするスピーカーレイアウトが提唱されており、これによりライブ会場の最前列や、楽器に囲まれた感覚を再現する上で強力な効果を発揮します。

両技術の比較
以下の表は、ドルビーアトモスと360 Reality Audioの主要な技術的特徴を比較したものです。
項目 | ドルビーアトモス (Dolby Atmos) | Sony 360 Reality Audio |
技術的基盤 | 独自規格 (AC-4, Dolby Digital Plus等) | MPEG-H 3D Audio (国際標準) |
最大オブジェクト数 | 128 (118個のオブジェクト + 10個のベッド) | 64 (制作環境により変動) |
空間の考え方 | 7.1.4 等のグリッドベース | 13.0 等の球状レイアウト |
特徴的な利点 | 広範なデバイスサポートと制作環境の統合 | 球状音場による足元からの音響再現 |
3次元空間情報生成の物理的・心理音響学的原理
イマーシブオーディオが、わずか二つのスピーカーやヘッドフォンから「背後」や「頭上」の音を感じさせることができるのは、人間が音の位置を特定するために利用している「心理音響学的キュー(手がかり)」を高度にシミュレーションしているためです。
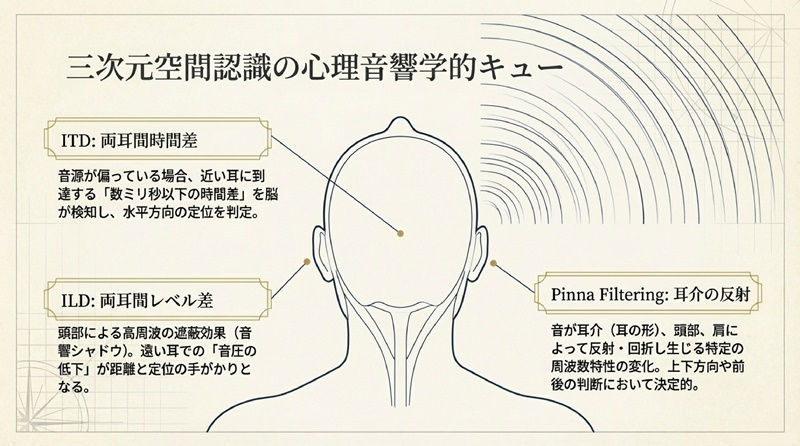
空間認識の三要素:ITD、ILD、そしてHRTF
人間は、左右二つの耳に到達する音のわずかな差異を脳で処理することで、音源の方向と距離を推定しています。
両耳間時間差 (ITD): 音源が左右どちらかに偏っている場合、その音は近い方の耳に先に到達します。この数ミリ秒以下の時間差を脳が検知し、水平方向の定位(角度)を判定します。
両耳間レベル差 (ILD): 高周波の音は頭部によって遮蔽されるため、音源から遠い方の耳では音圧が低下します。この強弱の差が定位の手がかりとなります。
頭部伝達関数 (HRTF): 音が耳に到達するまでに、耳介(耳の形)、頭部、肩、胴体によって反射・回折し、特定の周波数特性が変化します。特に上下方向(仰角)や前後の判断において、耳介による複雑なフィルタリングが決定的な役割を果たします。
数学的に、HRTFは音源の位置 と周波数 の関数として定義されます。ある音源信号 がリスナーの鼓膜に到達したときの音圧 は、以下の複素伝達関数として記述できます。

ここで が左耳および右耳のHRTFです。デジタルオーディオ処理において、各オーディオオブジェクトの座標に基づきこの関数の演算を行うことで、ヘッドフォン上に仮想的な3D空間を再現します。
パーソナライズされたHRTFの重要性
HRTFは個人の耳の形や頭の大きさに依存するため、汎用的なダミーヘッドのデータを使用すると、定位の不鮮明さや音が頭の中で鳴っている感覚が生じることがあります。これを解決するために、Appleやソニーはスマートフォンのカメラを用いて耳をスキャンし、個人の解剖学的特徴から最適なHRTFを推定・生成する「パーソナライズ・空間オーディオ」を導入しています。
AppleはiPhoneのカメラを利用して顔と耳の3D表現を作成し、ソニーは耳の写真から機械学習を用いて聴取特性を予測するアルゴリズムを使用しています。これにより、個人の耳の形状に最適化された、より没入感の高い体験が可能となります。

AI時代におけるコンピュテーショナルオーディオの変革
AIと深層学習(ディープラーニング)の導入は、空間情報の「キャプチャ」と「生成」の両面で革命をもたらしました。従来の物理的なマイク設置による録音に加え、演算によって空間情報を創造する「コンピュテーショナルオーディオ」が注目を集めています。
アップミキシングと音源分離:既存資産の3D化
過去の膨大なモノラルやステレオの録音資産を3D化するために、AIを用いた音源分離(MSS)とアップミキシング技術が不可欠となっています。
音源分離モデルの活用: 混合されたステレオ信号から、ボーカル、ドラム、ベース、その他の楽器を高い精度で分離します。波形ベースのモデルを用いることで、従来の手法よりも極めてクリアな抽出が可能となっています。
深層学習によるアップミキシング: 最新の技術では、ニューラルネットワークを用いてステレオ音源からアンビエンス(環境音)成分を抽出し、元の音源の位相を壊すことなくサラウンドチャンネルへ再配置します。これは従来の信号処理手法で見られた不自然な響きを大幅に低減させます。

拡散モデルによる空間生成と視覚情報の活用
画像生成で成功を収めた拡散モデル(Diffusion Models)やフローマッチング技術がオーディオ分野に転用され、物理的に整合性のある空間情報を「演算」のみで作り出すことが可能となりました。
ビデオ映像からの音響生成: AIフレームワークを用いることで、ビデオ映像から音源の3D軌跡(座標と深さ)を推定し、それに一致するバイノーラル音声を自動生成することが可能になっています。
生成的空間合成: 音源の種類と空間座標を指定することで、多チャンネルの空間オーディオを直接合成する技術も登場しています。これにより、モノラル音源から高品質な空間音響を効率的にサンプリングできます。
ビジュアル・アコースティクス:視覚情報からの音響空間再構築
最新のシステムでは、映像内のオブジェクト検出と深さ推定を行い、それに基づいてモノラル音声を自動的に空間化することが可能です。これはビデオ会議の音声最適化から、アマチュアクリエイターによるイマーシブコンテンツ制作まで、幅広い応用が期待されています。特に、大規模言語モデルを制御役として機能させ、自然言語の指示から楽器の配置や残響パラメータを決定するハイブリッドな手法も提案されています。

空間情報のキャプチャとデジタルツインの構築
現実世界の音響空間をデジタル空間に再現(デジタルツイン)するためには、音の到来方向だけでなく、その場所特有の「響き」を精緻に捉える技術が必要です。
アンビソニックスと球面マイクアレイ
シーンベースのオーディオキャプチャにおいて、アンビソニックス(Ambisonics)は最も重要な技術です。これは音場を球面調和関数で分解して記録する手法であり、マイクの向きに依存しない「全方位の音響情報」を保持できます。高次のアンビソニックスを用いることで空間解像度が向上し、リスナーが空間内で頭を動かしても、極めて正確な定位を維持できるようになります。

LiDARを活用したアコースティック・デジタルツイン
現在、最も先進的なアプローチは、LiDAR(光検出とレンジング)による幾何学スキャンと音響計測の融合です。
LiDARによる空間データ化: 携帯型の空間スキャナーは、LiDARを用いて建物の幾何学構造をミリメートル単位の精度でデジタル化します。
音響再現システム: スマートフォンのカメラとマイクを使い、部屋の3Dメッシュを作成しながら部屋の響き(インパルス応答)を動的に計測するシステムが開発されています。
ニューラル音響フィールド: 空間内の限られた地点で録音されたデータから、空間内のあらゆる地点における音響特性(残響、遮蔽、回折)をAIが学習・再現する技術も注目されています。

今後の進化の方向性:6-DOFとメタバースへの統合
イマーシブオーディオの次なるステップは、固定された地点からの聴取から解放され、完全なインタラクティビティを実現することです。
MPEG-I Immersive Audio:次世代の標準規格
現在標準化が進んでいる「MPEG-I」は、VR/AR時代を見据えた真の3Dオーディオ規格です。従来の技術が頭の回転(3-DOF)のみに対応していたのに対し、MPEG-Iは空間内の「位置の移動(6-DOF)」をフルサポートします。これにより、リスナーが空間内を自由に歩いたり、音源に近づいたりすることが可能になります。

リアルタイム・オーディオ・レイトレーシング
グラフィックスの分野で普及したレイトレーシング(光線追跡)が、音響シミュレーションにも本格的に導入され始めています。GPUの演算能力を用いて、仮想空間内の音波の反射をリアルタイムで計算します。これにより、扉が開閉したり壁の材質が変わったりした際に、音の響きが即座に変化する動的な環境適応が可能となります。

おわりに
イマーシブオーディオは、単なる「スピーカーを増やす技術」から、物理学、心理音響学、そして最新の生成AI技術が融合した「空間コンピューティング」の一環へと変貌を遂げつつあります。ドルビーアトモスが商用的なエコシステムを盤石にする一方で、ソニーの360RAが追求した全天球的な没入感は、次世代のMPEG-Iや6-DOFオーディオへとその思想を繋いでいます。
AIの台頭は、音響制作の民主化を加速させています。かつては専門のスタジオが必要だった3D音響制作が、現在ではAIによる音源分離とコンピュテーショナルな空間生成により、個人のクリエイターの手元で実現可能となっています。同時に、LiDARやニューラル音響フィールドの研究により、現実の音響空間を「計測」するのではなく「学習」し、それを仮想空間で自由に再構成・編集できる時代が到来しています。
今後の課題は、これらの高度な演算処理をいかに低遅延でモバイルデバイスにおいて実行するかという点にあります。パーソナライズの精度向上とリアルタイム・シミュレーションの最適化が達成されたとき、オーディオは私たちが「その中に存在する環境」そのものへと進化を遂げるでしょう。




コメント